Sybil Is a Funnel: Our Approach to A/B Testing Complex Agentic Systems

Whether we’re rolling out a new model, a new prompt, or a new stage in our pipeline, we continuously ship meaningful changes to Sybil. Prior to each feature landing, we ask ourselves the same question: will this change make Sybil better for our users?
To answer this, we’ve built a diverse set of production-worthy web apps to use as internal ranges. We've also adopted a measurement framework that lets us run Sybil against these ranges at the granularity each product question demands, making our benchmarks more efficient without sacrificing their realism. In this blog post, we’ll talk about how we measure Sybil, how agentic systems like Sybil can be thought of as a funnel, and how this framing enables faster and leaner A/B testing.
What gets measured?
Sybil's job is to surface correct, high-impact findings. We measure Sybil’s performance on our ranges using four key metrics:
- Recall - of the exploitable vulnerabilities that exist in a target, what fraction does Sybil find? This is measured against a golden set of verified vulnerabilities in our internal testing ranges.
- Precision - of the vulnerabilities Sybil reports, what fraction are confirmed true positives with real business impact? This is the signal-to-noise ratio that determines whether users trust the output.
- Latency - how long does it take for users to receive findings and how long does each stage of our pipeline take to process them? This reflects the friction felt by users.
- Cost - how expensive is Sybil to run? This is our own internal friction.
These core metrics pull against each other in practice. A system that flags everything as a vulnerability has perfect recall but abysmal precision; users will stop trusting the system within a week since it’s too noisy to actually be useful. A system that surfaces only the obvious findings will have high precision but might miss the subtle, chained vulnerabilities that could matter more. Cost and latency add more pressure: we could always improve recall by spending more compute, but an engagement that costs 10x more and takes 3x longer isn't necessarily a more useful product.
What’s a funnel?
A traditional conversion funnel models user behavior: website visits → signups → activations → payments. Each transition has a conversion rate. Improving any single transition compounds through the rest of the funnel. By looking at drop-offs between stages, you can isolate where to optimize.
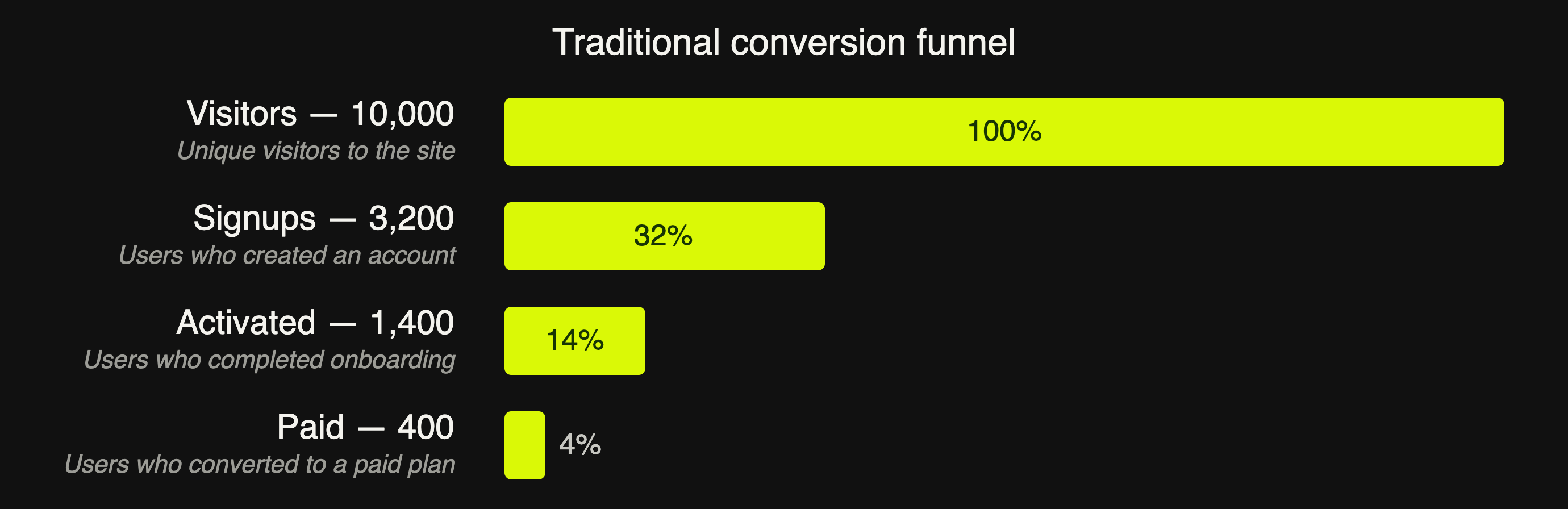
In a conversion funnel, visits → signups → activations → payments. Each stage depends on the one before it. You can A/B test a single transition by splitting traffic at that layer, but you can never really rerun the same users through both variants. Agent pipelines give us something more powerful! Because each stage's output is a concrete artifact, we can snapshot it and replay the exact same input through competing versions of the next stage.
How is Sybil a funnel?
Agent pipelines can work in a similar way. For our evals, we abstract Sybil’s pipeline into stages. Each stage has its own drop-off in true positives (real vulnerabilities we're tracking) and false positives (leads that don't pan out). Instead of optimizing for visits → payments, we optimize for true positives surviving the funnel and false positives getting filtered out, measuring our four metrics at each point in our funnel.
While the real version of Sybil is composed of many stages, we can use a simplified version of Sybil to help make this framing more digestible. Let’s say in our simplified version of Sybil, we have just four stages:
- A Discovery stage - agents spider the target and surface endpoints worth investigating. For example, they may flag all of the endpoints on a web app as leads to follow-up on, with some leads being actual vulnerabilities but a much higher number turning out to be dead ends. Recall starts strong here (we've covered the attack surface) but our signal-to-noise may start low.
- An Attack stage - agents investigate each endpoint lead and identify potential vulnerabilities. During this stage, these agents generally surface a large set of findings, a significant portion of which are true positives. While we may lose out on a small number of real vulnerabilities whose impact was too subtle for Sybil to prioritize in this stage, this stage helps substantially reduce how many false positives we have.
- A Verification stage - agents attempt to confirm and reproduce each finding. A strong Verification stage preserves true positives while aggressively filtering false ones.
- A Cleanup stage - agents deduplicate, calibrate severity, and run final alignment checks. At the end of a strong funnel, we end with a much higher number of true positives than false positives. Weak funnels end with a much higher number of false positives and few true positives.
Here's an illustrative example of how the shape of our funnel would change based on how well we’re doing:
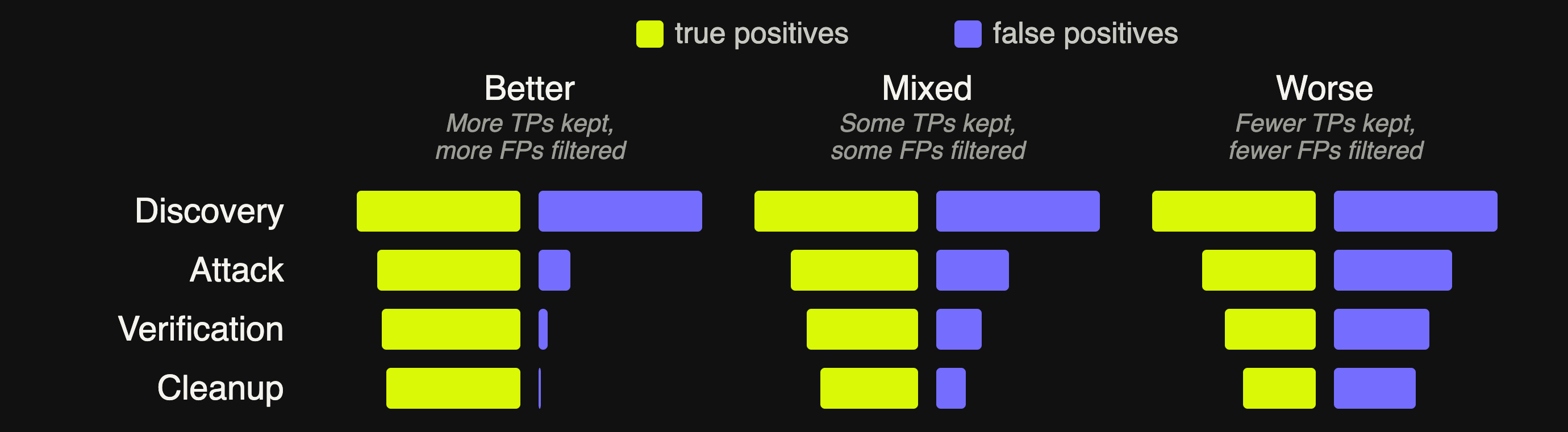
In the “Better” scenario, we see a strong drop-off in false positives at each stage of the funnel while true positives are hardly impacted. Looking at the “Worse” scenario, we see the opposite - about as many true positives as false positives are being dropped at every stage. In the “Worse” scenario, instead of these stages helping to improve our precision, we only see our recall degrade over time as true positives get dropped.
Replaying the funnel
Because findings move through Sybil in a known shape, we can snapshot state at different layers of Sybil’s pipeline and replay Sybil from there. These snapshots let us test a single stage, a chain of stages, or the whole pipeline end-to-end against the same ranges using the same set of known vulnerabilities.
For example, we can run Sybil up until the Attack stage, snapshot our state, then run a sweep across different models in the Verification stage using that snapshot to find the model which gives us the best drop-off in false positives with the lowest drop-off in true positives. Instead of having to run Sybil end-to-end for each model we wanted to try out for the Verification stage, we only had to run Sybil up until the Attack stage once to get a seed snapshot, then reuse that snapshot to run only the Verification stage for each model we wanted to test.
Why a funnel?
Viewing Sybil as a funnel helps us make smarter prioritization decisions, lets us sidestep making contrived or overly prescriptive benchmarks, and accelerates our evals without sacrificing their realism.
1. Locating improvement opportunities becomes easier
Knowing which stages have the biggest drop-off in true positives and where false positives survive the most helps us prioritize how we improve Sybil. To improve precision, we look at where false positives survive. Are false positives slipping past Verification? Could an Attack agent be generating a class of false positive our verifiers can't distinguish well? To improve recall, we look at where true positives drop off. Are Discovery agents missing endpoints associated with vulnerabilities? Are verifiers overly zealous?
2. Outcomes are rewarded instead of steps
By focusing on whether Sybil’s findings are true positives or false positives, we measure what Sybil achieves instead of how Sybil got there. Prescriptive benchmarks that check "did the agent call API X, then Y?" risk over-indexing on mimicry.
AlphaGo moments for cybersecurity, where agents find attack paths no human would consider, won't come from coercing agents into retracing conventional patterns.
Focusing on end outcomes also means we can add capabilities without rewriting our evals. When we introduced memories into Sybil, we didn't spend months building a contrived test for whether memories "looked right". Instead, we measured how the introduction of memories into our product impacted precision and recall through the funnel, and shipped based on that.
3. State seeding and stage scoping makes experimentation faster and leaner
Because each stage has a well-defined input and output, we can snapshot state at any boundary and replay only the downstream stages. Want to test a new verifier? Seed Verification with prior Attack output and measure how our metrics change with it. Want to compare two models at the Attack stage? Seed both with the same Discovery output and diff the results. When we expect a change to ripple downstream, we replay those stages too without rerunning the whole pipeline from scratch. A full Sybil engagement against a complex target can involve upwards of hundreds of thousands of LLM calls; state seeding and stage scoping turns what would be a handful of experiments per month into dozens per week.
What’s next?
Sybil doesn't stay still. Every release, the pipeline improves, the set of targets grows, and a new model shows up claiming state-of-the-art performance on a new benchmark. Release after release, the funnel gives us the flexibility and the efficiency to answer the question we started with: Will each change make Sybil better for users?